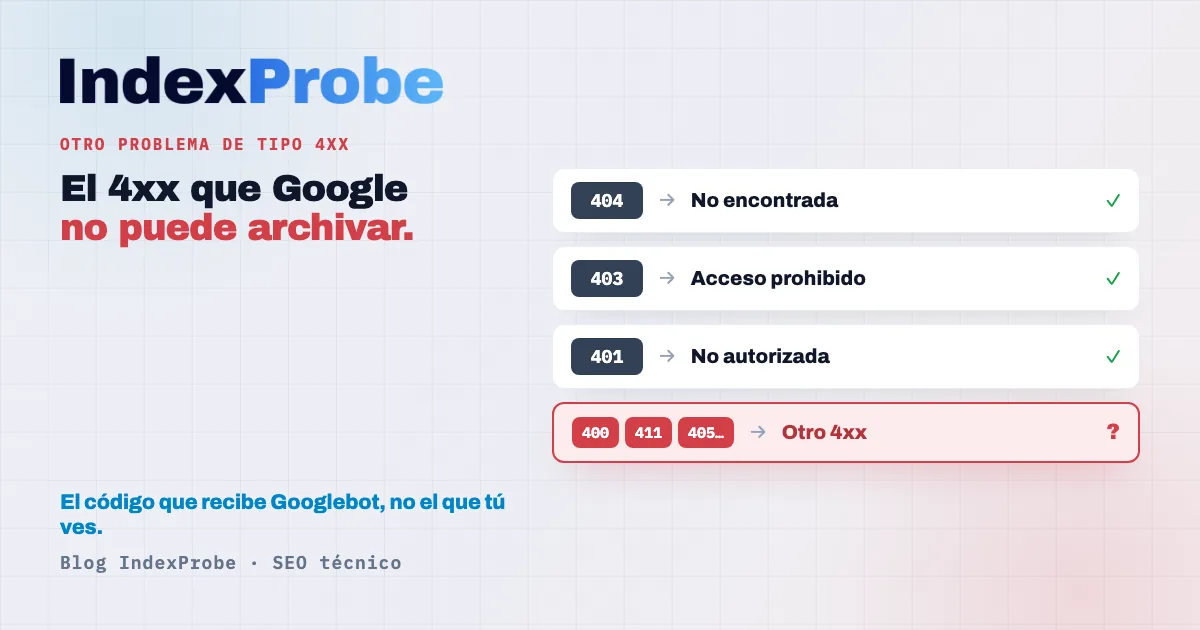
En el informe «Indexación de páginas» de Google Search Console, cada error 4xx habitual tiene su propia etiqueta: un 404 se convierte en «No se ha encontrado», un 403 en «acceso no permitido», un 401 en la suya. «La URL se ha bloqueado debido a otro problema de tipo 4xx» reúne todos los demás: el 4xx que Google constata pero no sabe dónde archivar.
¿De dónde sale este estado cuando ninguna de las etiquetas habituales encaja? ¿Por qué la página en cuestión se abre con toda normalidad en un navegador mientras que Googlebot, en cambio, topa con un error? ¿Y cómo encontrar, entre miles de URLs, las que comparten ese mismo 4xx silencioso?
Tres preguntas cuyas respuestas se alojan todas del lado de Googlebot, nunca del tuyo.
«Bloqueada por otro problema 4xx»: qué dice Google
Según la documentación oficial, este estado significa que «el servidor ha detectado un error 4xx que no está cubierto por ninguno de los problemas que se describen en este apartado». Es, literalmente, el cajón de los códigos huérfanos: todos los 4xx que Google encuentra pero no sabe etiquetar en ningún otro sitio.
La consecuencia sobre la indexación es tajante. Cuando Googlebot recibe un 4xx, considera que la página no se sirve correctamente y no la indexa. La página sale del índice si estaba en él, o no entra nunca si es nueva.
Lo que vuelve difícil este estado es precisamente su anonimato: Google no publica ninguna lista de los códigos que aterrizan aquí. Los únicos códigos colocados de forma explícita en otro sitio están documentados. Un 404 o un 410 pasan a «No encontrada (404)», un 401 tiene su propio motivo, un 403 pasa a «acceso prohibido (403)». Todo lo demás cae en este cajón, con una excepción: un 429 (demasiadas solicitudes) se trata como un error de servidor (5xx), no como un 4xx clásico.
Aquí vs en otro sitio: qué códigos 4xx caen aquí
El estado agrupa los 4xx que Google no clasifica de otro modo. En la práctica, casi siempre un 400 (petición mal formada) o un 411 (falta la cabecera Content-Length), a veces 405, 406, 422 o 451 según la configuración del servidor. Los códigos más habituales, en cambio, se archivan bajo una etiqueta propia en la Search Console.
| Código que recibe Googlebot | se archiva | Estado GSC |
|---|---|---|
| 400, 411 (y, según configuración, 405 / 406 / 422 / 451) | AQUÍ | Bloqueada por otro problema 4xx |
| 404, 410 | en otro sitio | No encontrada (404) |
| 401 | en otro sitio | Bloqueada por una solicitud no autorizada (401) |
| 403 | en otro sitio | Bloqueada por acceso prohibido (403) |
| 429 | en otro sitio | Error de servidor (5xx) |
Quédate con el principio antes que con la lista: si un 4xx no tiene etiqueta propia, acaba aquí. Como Google no documenta la composición exacta de este cajón, el reflejo útil no es adivinar el código, sino ir a leer el que Googlebot ha recibido de verdad.
La trampa: la página se abre en el navegador, pero Googlebot recibe un 4xx
Esto es lo que desconcierta a la mayoría de los SEO ante este estado: la página se muestra a la perfección cuando la abres, y la Search Console se empeña en marcarla como error. El reflejo es dar por hecho que se trata de un falso positivo. Casi siempre es un error de lectura.
La razón responde a una asimetría sencilla: lo que ve tu navegador no es lo que recibe Googlebot. Tú llegas desde tu dirección IP, tu user-agent, tus cookies de sesión, tus cabeceras habituales. Googlebot llega desde los rangos de IP de Google, con su propio user-agent, sin cookie ni sesión. Una regla que distingue esos dos perfiles puede servir un 200 a uno y un 4xx al otro, sin que nada asome por tu lado.
El único veredicto que cuenta no es, por tanto, lo que tú ves, sino el código que Google ha recibido. Mientras pruebes desde tu equipo, mides tu propio acceso, no el de Googlebot.
Leer el código exacto que recibe Googlebot (prueba en vivo)
Para zanjarlo, abre la herramienta de Inspección de URLs de la Search Console y lanza «Probar la URL publicada». Google repite la petición en tiempo real con Googlebot y te muestra el código HTTP realmente obtenido. Ese es el veredicto que da fe, no lo que muestra tu navegador.
Un curl o un navegador lanzados desde tu equipo pueden devolver un 200 mientras Googlebot recibe un 4xx: la IP, el user-agent y las cabeceras difieren, y suele ser sobre esos criterios sobre los que se apoya la regla bloqueante. Reproducir el código de Googlebot desde tu propio equipo resulta, así, poco fiable.
Queda un límite de método: esta prueba solo cubre una URL cada vez. Para una página aislada, basta. En cuanto el estado afecta a un lote de URLs, inspeccionarlas a mano se vuelve enseguida impracticable, un punto sobre el que volvemos más abajo.
Por qué Googlebot recibe otro 4xx: las causas
En la práctica totalidad de los casos, ese 4xx viene de una capa entre Googlebot y tu aplicación, no del contenido de la página. Una regla de seguridad, un CDN o un mecanismo anti-bot intercepta la petición de Googlebot y le devuelve un código de error que nada expone en un navegador normal.
La primera causa que examinar es el cortafuegos de aplicación (WAF), el CDN o la solución anti-bot. Muchos de estos dispositivos filtran el tráfico automatizado y, en lugar de responder con limpieza, sirven un 4xx atípico a todo lo que se parece a un robot, Googlebot incluido. Una regla «challenge» mal calibrada, una protección DDoS demasiado amplia o una lista de bloqueo por user-agent bastan para desencadenar el problema.
El rate-limiting es una trampa frecuente e insidiosa. Cuando tu servidor considera que Googlebot lo consulta con demasiada frecuencia, debería responder con un 429. Algunas configuraciones devuelven en su lugar un 4xx genérico: en vez de indicar «ve más despacio», indican «acceso denegado». Google archiva el 429 del lado de los errores de servidor (5xx) y sabe interpretarlo, pero un 4xx mal elegido lo despista y lo manda a este cajón.
Vienen luego causas más técnicas. Una cabecera Accept que tu servidor juzga incompatible puede producir un 406 (Not Acceptable). Un método HTTP que Googlebot emplea y que tu servidor rechaza puede devolver un 405 (Method Not Allowed). Un 411 aparece si el servidor exige una cabecera Content-Length ausente de la petición. Por último, un filtrado geográfico o por rango de IP puede bloquear los servidores de Google si no están autorizados de forma explícita.
Ahora que conoces las causas posibles, falta saber cuáles de tus URLs están afectadas.
A escala: aislar las URLs que comparten el mismo 4xx silencioso
Este estado tiene una particularidad: rara vez es masivo, más bien minoritario y disperso. Unas pocas páginas atrapadas en una regla de WAF, un directorio entero tras una protección mal ajustada, URLs servidas por un CDN concreto. Inspeccionar cada URL una a una en la Search Console para dar con ellas no es sencillamente viable.
El reto está en agrupar de un vistazo todas las páginas que reciben el mismo código de rastreo, y luego detectar un punto en común (un prefijo de URL, un segmento, un patrón de URL). Es lo que permite una lectura por código de rastreo aplicada al conjunto de tus URLs, en lugar de URL por URL.

Ese es justamente el trabajo de IndexProbe. Sobre una lista de URLs que le proporcionas (sitemap, CSV, export de rastreo) o que construyes desde la GSC, la herramienta consulta la API de la Search Console y devuelve, para cada página, el código de rastreo que Googlebot ha recibido de verdad, fechado en su último paso. Filtras las páginas en «otro 4xx», las cruzas por segmento y el punto en común salta a la vista. IndexProbe no es un rastreador: solo analiza las URLs que le das, nunca descubiertas siguiendo enlaces.
💡 Detectar estos 4xx silenciosos en todo un sitio, de una URL en una, no es viable. IndexProbe inspecciona tu lista de URLs vía la API de Search Console y devuelve, por página, el código que Googlebot recibió de verdad, fechado en su último paso. Probar IndexProbe en acceso anticipado →
Corregir: permitir Googlebot correctamente
La corrección se juega casi siempre en la capa que sirve el 4xx, nunca en el contenido de la página. Empieza por localizar al responsable: WAF, CDN, solución anti-bot o regla de la aplicación. La prueba en vivo te ha dado el código exacto; ese código orienta directamente la capa que hay que inspeccionar.
Para permitir Googlebot, el buen método es la verificación por DNS inverso, no el user-agent. Un user-agent «Googlebot» se falsifica en una línea: incluir en la lista blanca solo esa cadena abre la puerta a los falsos robots. El método fiable consiste en hacer un DNS inverso sobre la IP que se presenta, comprobar que resuelve hacia un dominio googlebot.com o google.com, y confirmar luego con un DNS directo que ese dominio apunta de verdad a la IP de partida. También puedes apoyarte en los rangos de IP oficiales que Google publica.
Para lo demás, las correcciones son mecánicas. Si el rate-limiting devuelve un 4xx, reconfigúralo para que responda con un 429 acompañado de una cabecera Retry-After: Google entiende esa señal y va más despacio sin dejar de referenciar. Si un 406 viene de una negociación de contenido demasiado estricta, relaja la gestión de la cabecera Accept. Si un 411 bloquea el rastreo, comprueba que el servidor no exige un Content-Length en peticiones que no lo llevan. Una vez corregida la regla, vuelve a lanzar una prueba en vivo para confirmar que Googlebot obtiene ya un 200.
Comprobar que la corrección ha funcionado
Una corrección nunca está lograda mientras Google no la haya constatado. Dos señales lo confirman: una prueba en vivo que devuelve 200, y luego el cambio de estado tras un nuevo paso de Googlebot. Ese nuevo rastreo no es inmediato: cuenta con unos días o unas semanas según la frecuencia de rastreo de la página.
La prueba en vivo valida el instante presente, pero es la comparación de dos análisis sucesivos la que muestra el cambio real en el índice. Ves el lote de URLs abandonar el estado «otro 4xx» y volver a indexadas.

El mismo reflejo vale para la vigilancia continua. Una puesta en producción, una nueva regla de WAF o un cambio de configuración del CDN pueden reintroducir el problema de un día para otro, sin alerta visible. Relanzar un análisis después de cada despliegue convierte un incidente silencioso en una señal detectable antes de la pérdida de tráfico.
💡 Una corrección de infraestructura solo se valida cuando Google la ha vuelto a rastrear. IndexProbe te da, por URL, el veredicto de rastreo oficial fechado en el último paso de Googlebot, sobre la lista que le proporcionas o que construyes desde la GSC, y sigue siendo repetible para seguir el cambio análisis tras análisis. Probar IndexProbe en acceso anticipado →
No confundir: 404, 403, 401 y «otro 4xx»
Estos cuatro estados comparten la misma familia de códigos pero exigen acciones opuestas. El reflejo correcto depende por completo de lo que Googlebot ha recibido, no de lo que tú ves.
| Código | Causa típica | Acción | Estado GSC relacionado |
|---|---|---|---|
| 404 / 410 | Página eliminada, URL errónea, enlace roto | Redirigir si procede, si no dejar que desaparezca | No encontrada (404) |
| 403 | Acceso denegado aunque la petición sea válida | Levantar la prohibición de acceso para Googlebot | Acceso prohibido (403) |
| 401 | Autenticación requerida | Retirar el muro de autenticación en las páginas públicas | Solicitud no autorizada (401) |
| Otro 4xx (400, 411…) | WAF / CDN / rate-limiting sirviendo un 4xx atípico | Corregir la regla de infraestructura, permitir Googlebot por DNS inverso | Otro problema de tipo 4xx |
Una última trampa merece atención: una página que responde 200 pero no contiene nada útil puede clasificarse como Soft 404, un caso que no tiene nada que ver con un código 4xx real. Y si Googlebot recibe un 5xx en lugar de un 4xx, es hacia el artículo Error de servidor (5xx) hacia donde hay que mirar.
Preguntas frecuentes
¿Qué es «Bloqueada por otro problema 4xx»?
Es un estado del informe «Indexación de páginas» de Google Search Console. Significa, según la documentación oficial, que «el servidor ha detectado un error 4xx que no está cubierto por ninguno de los problemas que se describen en este apartado». Es el cajón de los códigos 4xx que Google no archiva bajo una etiqueta propia. La página afectada no se indexa.
¿Qué códigos 4xx activan este estado?
Google no publica ninguna lista oficial de los códigos de este cajón. En la práctica, casi siempre un 400 (petición mal formada) o un 411 (falta Content-Length), a veces 405, 406, 422 o 451. Los códigos habituales tienen su propio estado: 404 y 410 (No encontrada), 401, 403, y 429 (tratado como error de servidor).
¿Por qué mi página se abre en el navegador pero Googlebot recibe un error?
Porque tu navegador y Googlebot no llegan con el mismo perfil: dirección IP, user-agent, cookies y cabeceras difieren. Una regla de WAF, anti-bot o CDN puede servir un 200 a tu equipo y un 4xx a Googlebot. Solo la prueba en vivo de la Inspección de URLs revela el código realmente recibido por Google.
¿Cómo corregir un error 4xx en la Search Console?
Localiza la capa que sirve el 4xx (WAF, CDN, anti-bot, aplicación) y permite Googlebot correctamente. Verifica su identidad por DNS inverso en vez de fiarte solo del user-agent, que se falsifica. Si el rate-limiting es la causa, responde con un 429 y una cabecera Retry-After. Vuelve a lanzar después una prueba en vivo para confirmar un 200.
¿Qué diferencia hay entre «acceso prohibido (403)» y «otro 4xx»?
El 403 es un código preciso y documentado: el servidor ha entendido la petición pero rechaza el acceso, y Google le reserva su propio estado. «Otro 4xx» agrupa todos los demás códigos 4xx sin etiqueta propia (400, 411, etc.). En resumen, un 403 está identificado por su nombre; el cajón «otro 4xx» cubre lo que Google no sabe clasificar en ningún otro sitio.